Whisper手动下载模型:
使用教程
1,下载模型.
2,复制模型文件到模型储存位置
3,选择下载的模型
4,验证模型是否可用
*推荐在苹果M芯片电脑使用,非M芯片目前识别特别慢.
*模型文件大小越大准确率越高识别时间越久.
*模型文件名称带有“en”或者“English”为纯英文模型对英文识别率更高.其他为多语言模型
*通常默认选择“Medium”(1.53GB)模型.
下载链接:
- 百度网盘下载:
- 链接: https://pan.baidu.com/s/1NWI90jc62xn4DzvKF92lYg?pwd=3c5g 提取码: 3c5g
- 备用下载(海外网络推荐):
WIN版本Whisper模块N卡GPU加速安装:
雨伞视频字幕提取语音识别模块whisper 启动N卡cuda GPU加速(win版本有效)
GPU语音识别模块下载: 链接: https://pan.baidu.com/s/13nAQInhx_589IQiTyzskSw?pwd=slsw 提取码: slsw
安装教程:
1,先安装雨伞视频字幕提取 2.4以上版本
2,找到已经下载的GPU语音识别模块(cublas64_11.dll cublasLt64_11.dll cudart64_110.dll whisper.dll)大概641 MB大小
3,找到雨伞视频字幕提取的安装目录。默认路径在C:\Program Files\yssck\雨伞视频字幕提取(UVS OCR)。
4,拷贝GPU语音识别模块覆盖到安装目录。
5,完成
PaddleOCR手动下载模型:
使用教程:
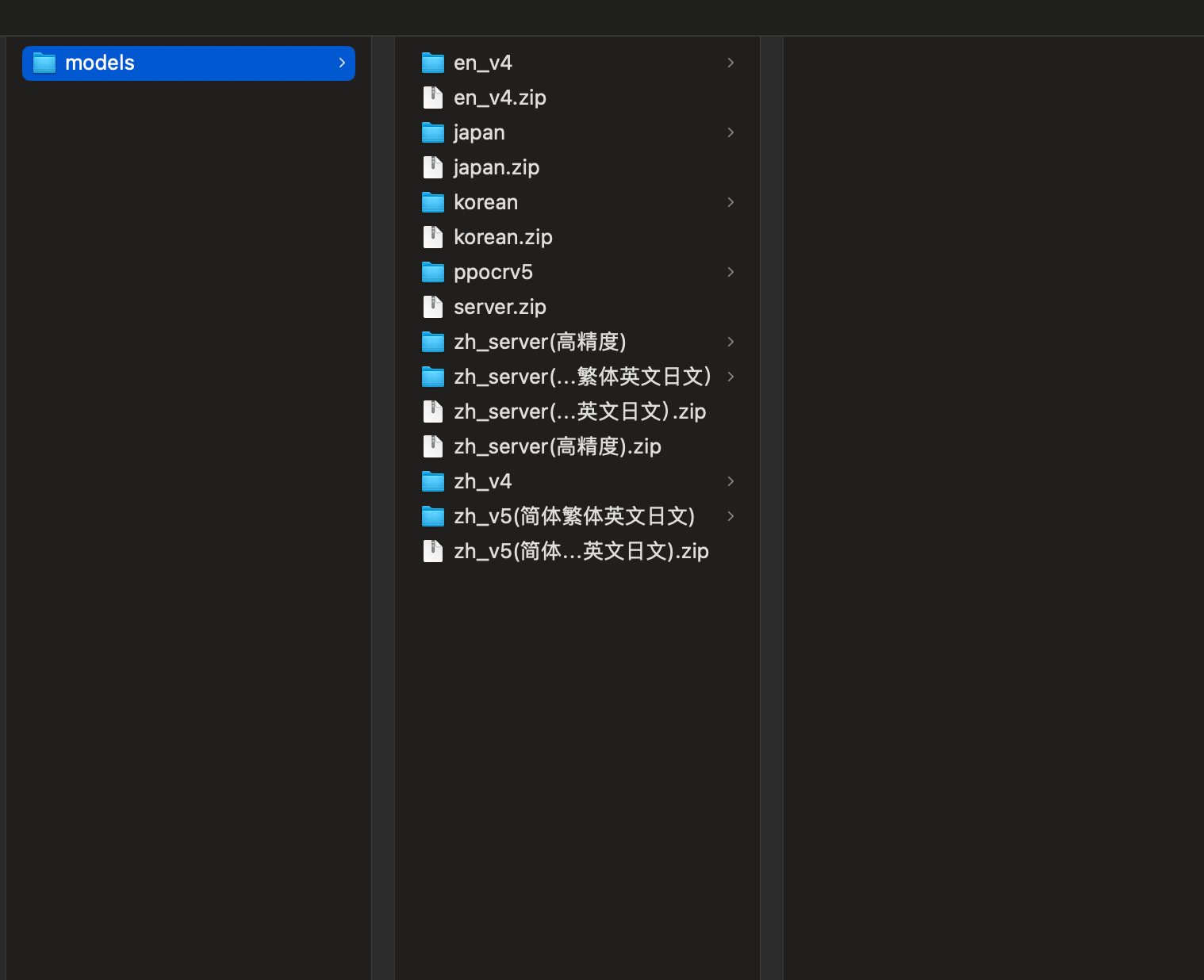
下载模型文件夹(一个文件夹里面有4个模型文件rec.onnx,cls.onns,det.onnx,keys.txt,四个文件)- >放到模型储存位置->点击刷新,选择正确的模型文件夹->验证是否可用-> 重新添加识别文件.
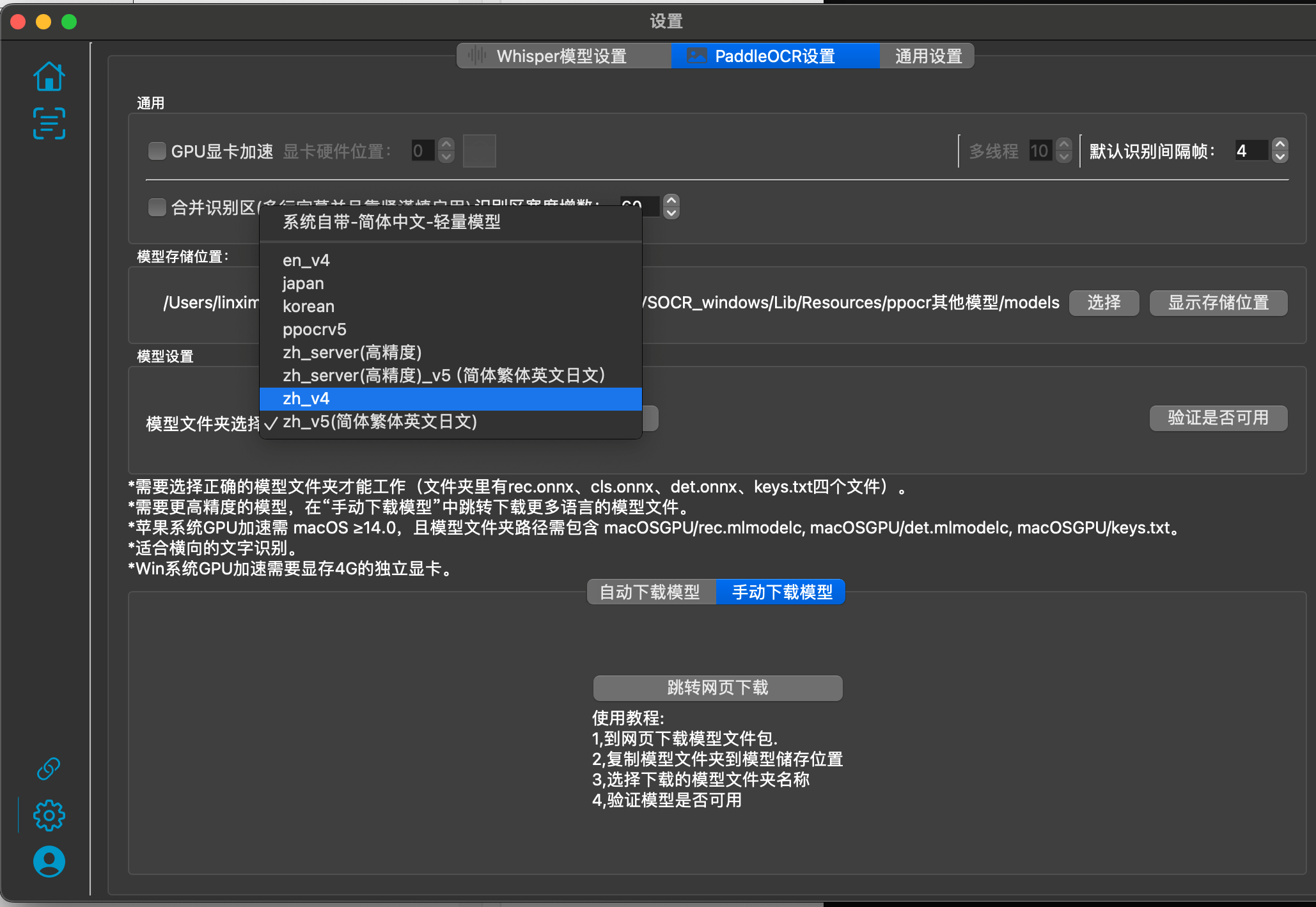
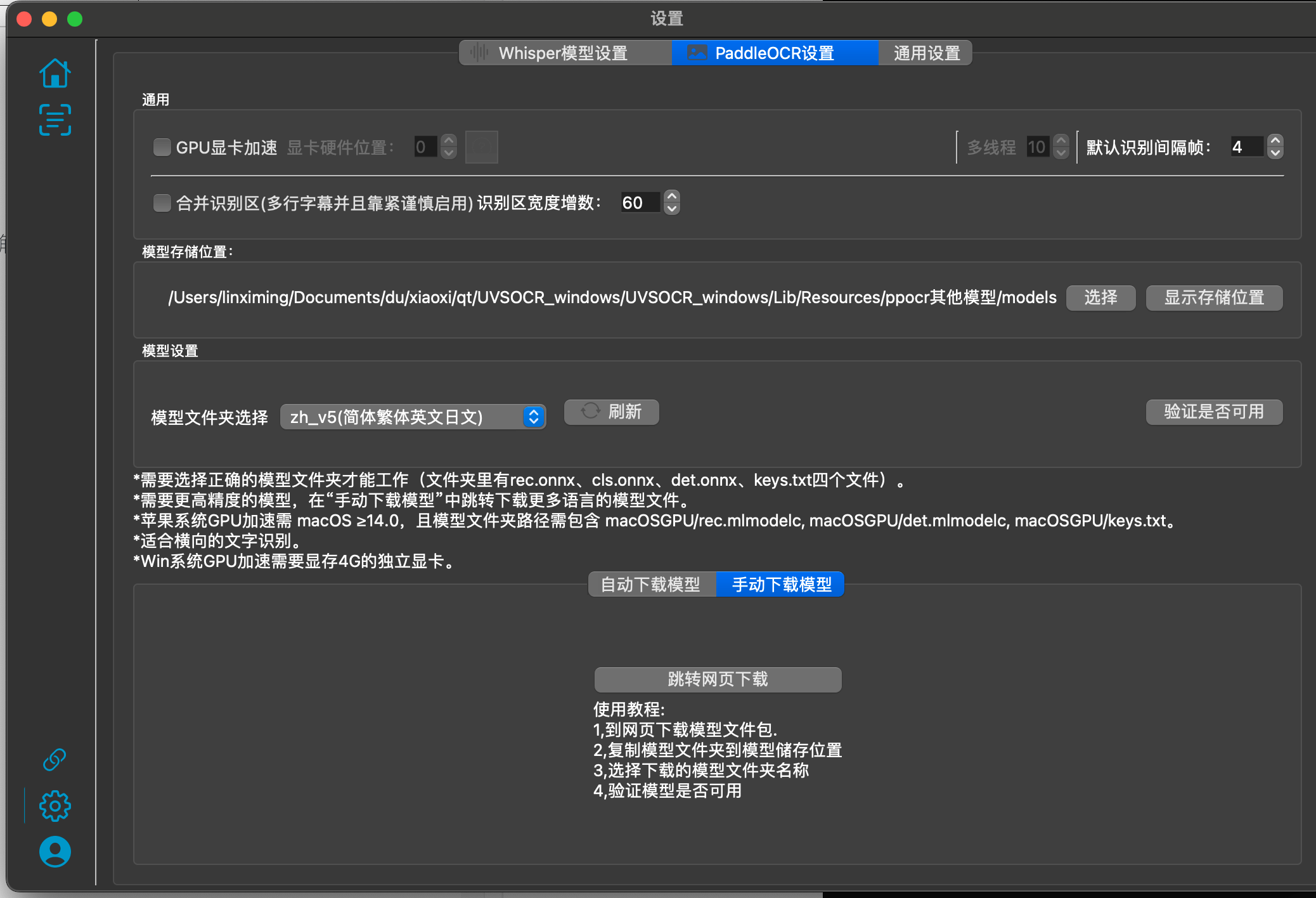
下载地址:
V5版本百度网盘下载链接: https://pan.baidu.com/s/1g6W0ojfpxt_EojBioqw12g?pwd=0fdd 提取码: 0fdd
- 🌐 单模型支持五种文字类型(简体中文、繁体中文、中文拼音、英文和日文)。
- ✍️ 支持复杂手写体识别:复杂连笔、非规范字迹识别性能显著提升。
- 🎯 整体识别精度提升 – 多种应用场景达到 SOTA 精度, 相比上一版本v4,识别精度提升13个百分点!
或者海外用户(下载是zip需要解压):https://drive.google.com/file/d/1EAghDlO1x29dILvGa-dSl5Vr85itcvVH/view?usp=sharing, https://drive.google.com/file/d/1yYBjNTKozwXVH5bNhv7G2SsPtCwnXYSp/view?usp=sharing
V4版本百度网盘下载链接:
- 链接: https://pan.baidu.com/s/1BzGEsj0r1Np7FYvklXxpzg?pwd=ezz5 提取码: ezz5
备注:
- 1.5之前的旧版本的模型文件对应了“server_v2(简体中文高精度)”
- 新版软件自带轻量级简体模型无需配置
模型文件夹目录结构演示:
–模型文件夹存储位置
- 模型文件夹(名称:server_v2(简体中文高精度))–里面有文件(rec.onnx,cls.onnx,det.onnx,keys.txt)四个必要文件
- 模型文件夹(名称:server_v4(简体中文高精度))–里面有文件(rec.onnx,cls.onnx,det.onnx,keys.txt)四个必要文件
- …
1.5旧版本使用 新版本不再适用:
下载模型(2个都要下载)- >放到模型储存位置->点击刷新,选择正确的模型->验证是否可用-> 重新添加识别文件.
rec模型选择通常选择ch_ppocr_server_v2.0_rec_infer.onnxdet模型选择通常选择ch_ppocr_server_v2.0_det_infer.onnx
下载地址:
百度网盘下载(链接里有2个文件均要下载):链接: https://pan.baidu.com/s/1aVUuDXZ-iJgYHOdI7Ah8Qg?pwd=e5j2 提取码: e5j2